
stephen ingram
- Principal Backend Software Engineer/Data Analyst for RISC Networks
For interested parties, this page describes both my working skill set and the different domains in which I have previous experience. I evidence these claims with a detailed list of my projects and publications.
Resume / Academic CV / Blog / LinkedIn

coding
As a developer, writing code is the major component of my regular workflow. I have experience building software with system-level languages like C, Python, and Java. For analysis and system administration, I have employed scripting languages like awk & Python to process and clean raw data files for input into databases, or data analysis environments like Jupyter and RStudio. A detailed list of familiar languages and software tools can be found on my experience timeline.
visualization
Looking at the data is a critical step in almost any data analysis. As part of the InfoVis group at UBC, I have discussed visualization techniques and evaluations since 2005. In my own experience, I use Tableau, or dplyr and ggplot2 for exploration of static tables, and GNU Octave/Matlab RStudio, and IPython Notebooks for iterative exploration while developing algorithms.
stats/machine learning
Stats/ML are a suite of techniques that help build predictive models of data distributions as well as give guidance about how much confidence to put in those models. As head of analytics at Coho Data, I have employed time-series analysis and clustering to analyze customer usage patterns. As a doctoral student, I have devised "unsupervised learning" techniques for data exploration. As a quant, I have used a variety of supervised learning techniques for fitting model parameters and statistical hypothesis testing for confirmatory analyses.
computer graphics
Familiarity with computer graphics APIs like WebGL/OpenGL has yielded at least two benefits for me as a researcher/analyst. First, I have leveraged the graphics pipeline to build novel visualization techniques that scale to large datasets. Second, I have exploited the parallelism of graphics processors (GPUs) to speed up existing analysis techniques.
data storage
My team and I have designed and developed an analytics system for analyzing storage product performance, events, and alerts. The system is deployed in AWS, is designed to easily scale with demand, and uses a flexible elasticsearch back end.
I have also developed different methods for analyzing the workload statistics of computer storage systems. I am interested in analyzing block-level storage traces for:
- classifying workloads
- optimizing flash provisioning
- predicting usage patterns
- empowering administrators
financial
My exposure to finance is on the trading side of things. I have researched the following:
- Order-book-level market-impact analysis
- Long-term trading system development (monthly)
- Short-term trading system development (daily)
- Trading algorithm ("Algo") development
- Automated trading system ("Bot") development
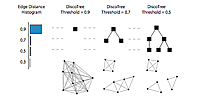
text analysis
I have been involved in several projects to help researchers navigate unordered collections of documents. These projects are:
- Overview
- Glimmer (see
docsexample) - Metacombine
scientific computing
My experience with scientific computing has focused on numerical linear algebra and nonlinear optimization, having taken graduate courses in both these topics. In my own research, I have experience with
- Nonlinear optimization techniques like Quasi-Newton methods
- Fast methods for exact matrix inverses like matrix reordering.
- Fast methods for approximate matrix inverses like Krylov subspace, and multigrid methods.
bioinformatics
I consulted with BC Cancer Agency to development software for analyzing DNA copy number alterations. The project involved collaborating with a lead researcher to design a visual console for analyzing copy numbers and labels across chromosomes.
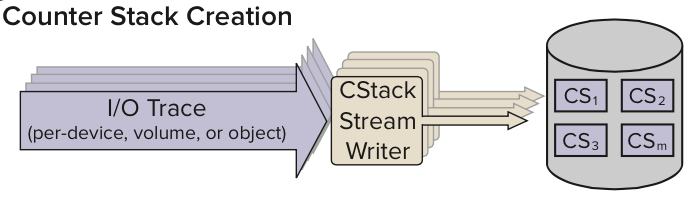
Counter Stacks
The Counter Stack is a compressed representation of a request stream. With Counter Stacks, one can calculate cache-usage statistics in sub-linear space for any time interval without storing the entire trace.

Color Thief
Color Thief is an iOS app for color transfer. It harnesses a fast GPU code I wrote for quickly swapping colors between photos using phone hardware.
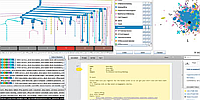
Overview
Overview is a tool for exploring large, unlabelled document datasets. It is targeted at helping journalists quickly analyze text dumps.
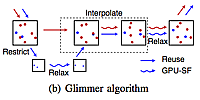
Glimmer
Glimmer is an algorithm for fast multidimensional scaling. Significant speed gains are achieved by leveraging GPU parallelism.
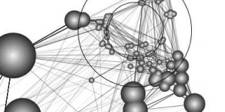
Small World Graph Visualization
I built a graph visualization tool based on Jarke van Wijk's paper using the prefuse toolkit.
MetaCombine
The MetaCombine Project at Emory University assessed using semantic clustering as a means of exploring digital libraries.
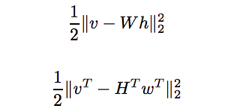
Nonnegative Matrix Factorization
This report describes an algorithm for computing fast nonnegative matrix factorizations.

Growbot
In 2004, my PC game, Growbot, was one of the Student Showcase winners in the Independent Games Festival.
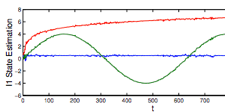
I1 Optimization
I1 is an algorithm for stochastic optimization based on Information Filtering. It is designed to complement the optimization algorithm called K1 based on the Kalman Filter.
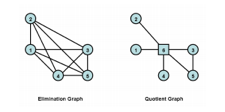
Minimum Degree Matrix Reordering Tutorial
I wrote a tutorial on different matrix reordering algorithms. Minimum degree matrix reordering increases the efficiency of the matrix inverse.
publications
- Dimensionality reduction for documents with nearest neighbor queries
- Stephen Ingram, Tamara Munzner. Neurocomputing 150, 2015.
- Visualizing dimensionally-reduced data: Interviews with analysts and a characterization of task sequences
- Matthew Brehmer, Michael Sedlmair, Stephen Ingram, Tamara Munzner. BELIV Workshop 2014.
- Characterizing storage workloads with counter stacks
- Jake Wires, Stephen Ingram, Zachary Drudi, Nicholas JA Harvey, Andrew Warfield. OSDI 2014.
- Overview: The design, adoption, and analysis of a visual document mining tool for investigative journalists
- Matthew Brehmer, Stephen Ingram, Jonathan Stray, Tamara Munzner. Infovis 2014.
- Practical Considerations for Dimensionality Reduction: User Guidance, Costly Distances, and Document Data
- Stephen Ingram, PhD Dissertation.
- Glint: An MDS Framework for Costly Distance Functions
- Stephen Ingram, Tamara Munzner. Proceedings of SIGRAD 2012.
- DimStiller: Workflows for dimensional analysis and reduction.
- Stephen Ingram, Tamara Munzner, Veronika Irvine, Melanie Tory, Steven Bergner, and Torsten Möller. IEEE VAST 2010.
- Glimmer: Multilevel MDS on the GPU.
- Stephen Ingram, Tamara Munzner, Mark Olano. IEEE Transactions on Visualization and Computer Graphics, 15(2):249-261, Mar/Apr 2009.
- Geometric Texture Synthesis by Example.
- Pravin Bhat, Stephen Ingram, and Greg Turk. Eurographics SGP 2004.
- Automatic Collage Using Texture Synthesis.
- Stephen Ingram, and Pravin Bhat. Smart Graphics 2004.
